Building a Habitat Supervisor for Kubernetes
October 6, 2017
Habitat is a project from Chef that provides you a reasonably simple way to build, package, and configure your application.
“Habitat is an integrated solution to building, running, and maintaining your application throughout its lifetime. It builds your application and its services into immutable artifacts with declarative dependencies, and then provides automatic rebuilds of your application and its services as your application code and dependencies have upstream updates.” - Habitat Getting Started Guide.
One of Habitat’s core features is that its Supervisor creates a gossip based cluster for managing configuration and state of your applications. Kubernetes also provides similar functionality this ability with the user defined Kubernetes manifests and the Kubernetes APIs. Initially it may seem odd that you would skip using Kubernetes to provide this functionality, however it does provide a way to have a universal system for your application management.
Personally I’m still on the fence about how useful it is to have this extra abstraction for application lifecycle management on top of what Kubernetes already offers, but I don’t discount it as something that could be useful in a lot of organizations.
Documentation for running Habitat built applications on Kubernetes is scant and feels fairly incomplete so I figured I would spend some time to work it out and come up with something myself.
Of course the first thing I had to do was decide on an application to build to demonstrate it. Initially I was going to use the basic tutorial app from the Habitat getting started tutorial, but instead decided I should write a very lightweight golang app to reduce the dependencies required to build and run it.
The application I wrote is dead simple. Just a few lines of Golang to provide an API that responds to a GET /health:
func main() {
handler := health.NewHandler()
http.Handle("/health/", handler)
http.ListenAndServe(":8080", nil)
}
After writing this simplest of applications I realized I had inadvertently created a way to run the Habitat Supervisor effectively standalone which would also allow me to bootstrap a Habitat Gossip Cluster that other applications can join as needed.
Next I had to get my Habitat environment set up. I was able to follow the Habitat Tutorial and figure out how to build this Golang app instead of a Ruby app. This was fairly straight forward and was some edits to a plan.sh file and a few hooks.
Performing the Build and exporting the .hart file to a Docker image was fairly easy after I stumbled my way through hab setup and getting a key etc working (the documentation for this could be improved to provide a more delightful experience).
Habitat Build Demo
$ git clone https://github.com/paulczar/habsup.git
$ cd habsup
$ hab studio enter
$ build
$ hab pkg export docker ./results/paulczar-habsuper-...hart
My next step was to test it using Docker to make sure the app started and cluster formed etc. This mean writing a simple docker-compose.yaml file to launch three containers and tell them how to connect to eachother with links. and then launch the containers and check that the exposed Habitat Supervisor API is accessible.
Docker Demo
$ git clone https://github.com/paulczar/habsup.git
$ cd habsup
$ docker-compose up -d
$ docker-compose logs -f
$ curl http://localhost:9631/services
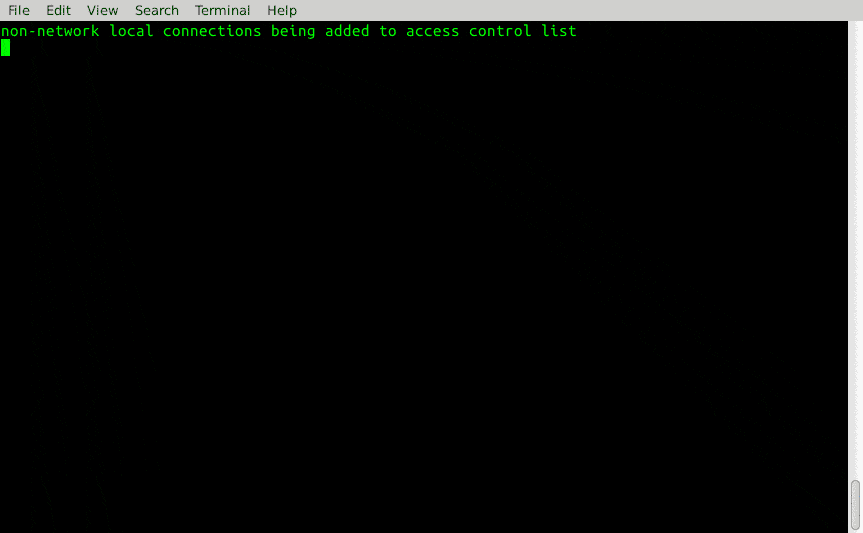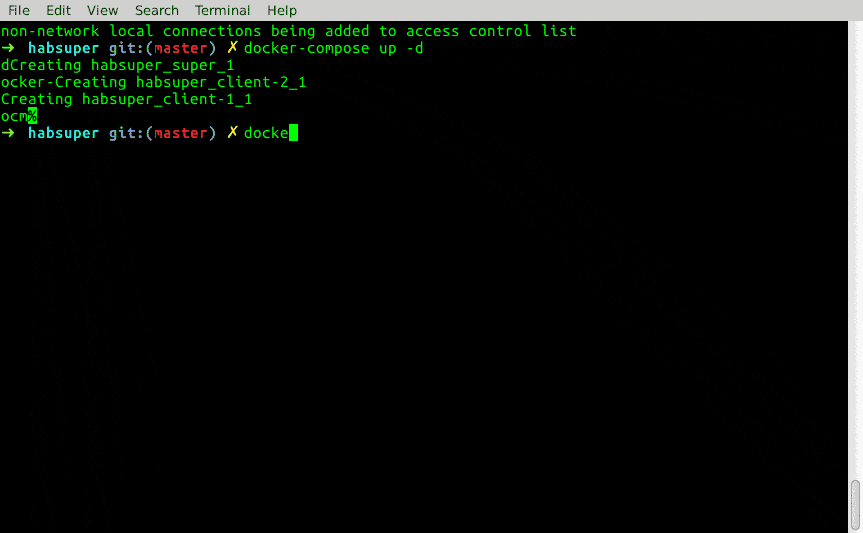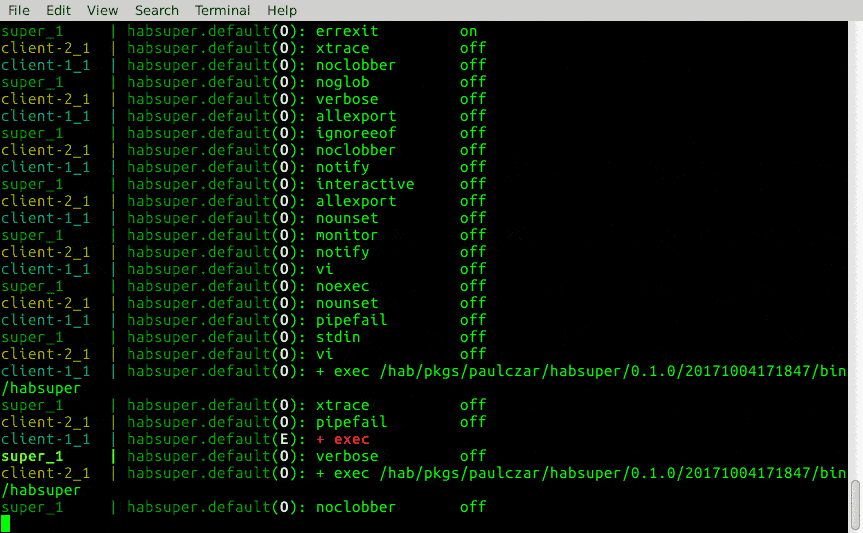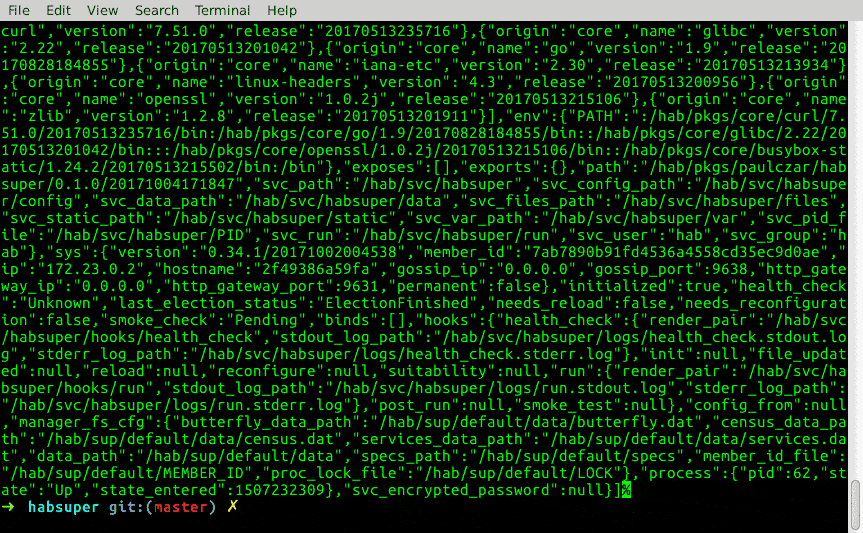
Note: you can see the habitat supervisors running the health check at the end once the containers are running.
Now that I had the Supervisor as a standalone image it was time to put together the appropriate Kubernetes manifest. To do so I had to do some research on the various Kubernetes resources and how they’d help me achieve my goal.
After some experimentation I decided that it made sense to use the StatefulSet resource for to run the supervisor in and run two services, the first being a headless service (meaning it is internal only) for the gossip protocol and the second being a regular service (with external access possible) for the API. Using a StatefulSet gave me predictable pod names and starts up the replicas in order which makes it much easier for the gossip protocol to work.
Initially I was using a single service for both the gossip and API ports but I wanted the Gossip to be internal only, but allow access (if needed) to the API. Creating two services gives me the ability to do both of those things. A headless service also has the benefit of creating a predictable KubeDNS entry for both the service and each pod which can come in handy.
Another interesting thing I discovered is that Kubernetes doesn’t publish the service DNS until at least one pod is running. This created a chicken-and-egg issue if I tried to use a readinessProbe for the hab api as habitat wouldn’t start until DNS was ready and DNS wouldn’t be created as it was waiting for a success from the probe. Thankfully there is an alpha feature that you can enable with an annotation service.alpha.kubernetes.io/tolerate-unready-endpoints: "true" that allows you to use DNS before the pods are ready.
Kubernetes Demo
$ git clone https://github.com/paulczar/habsup.git
$ cd habsup
$ kubectl create -f kubernetes/manifests
$ kubectl get pods -w
$ kubectl logs habitat-supervisor-0
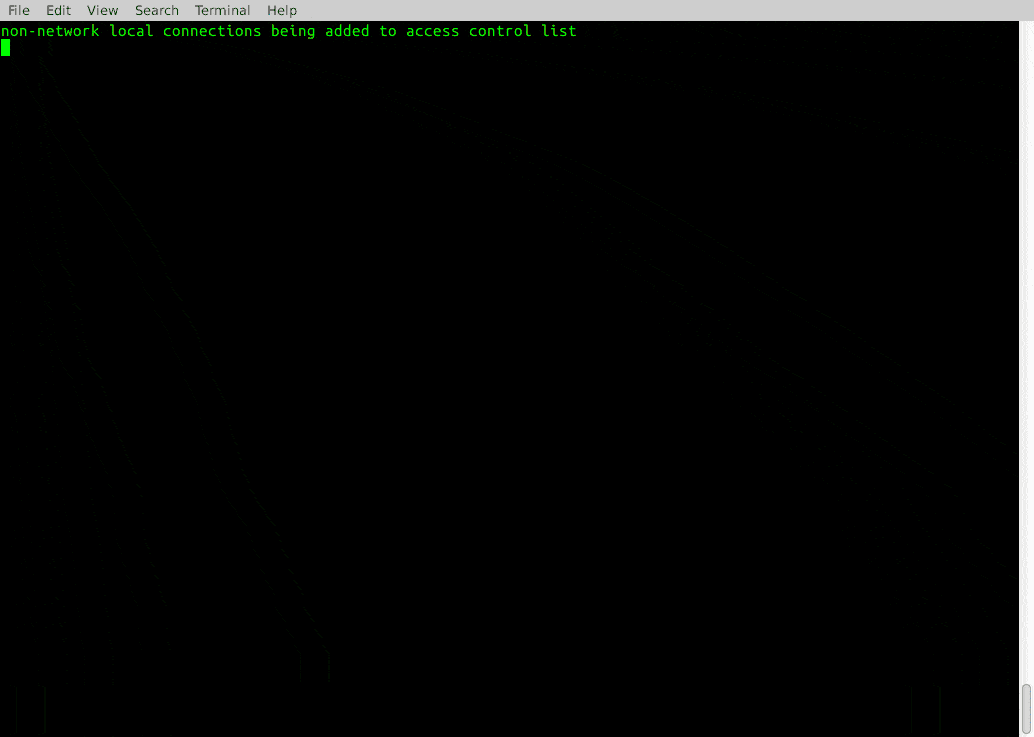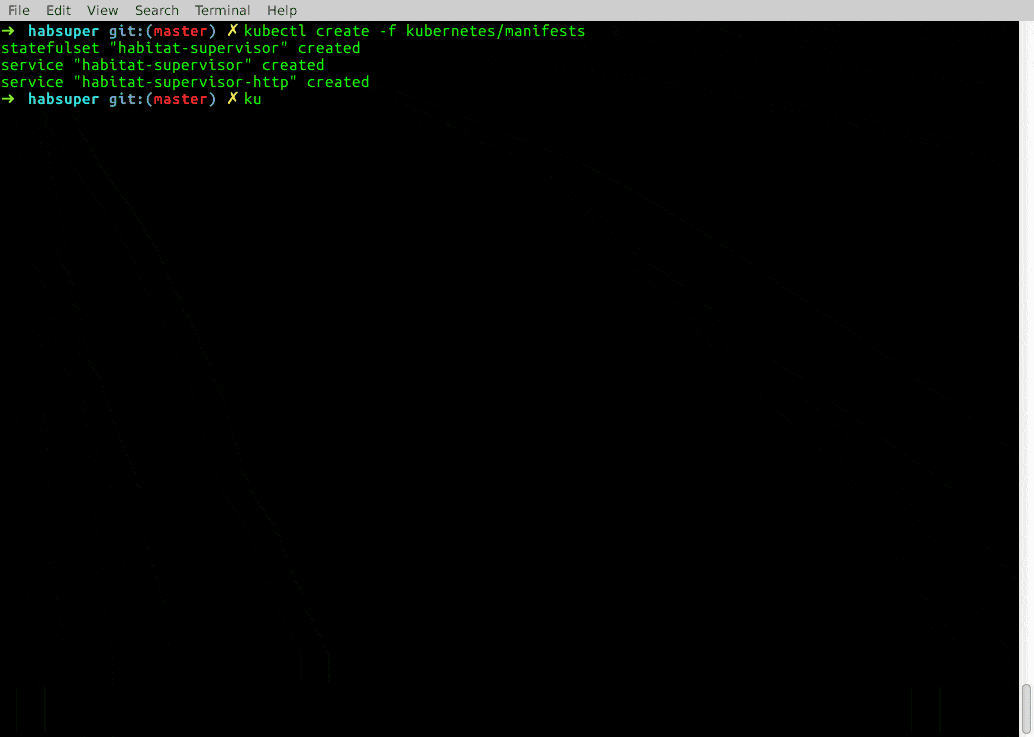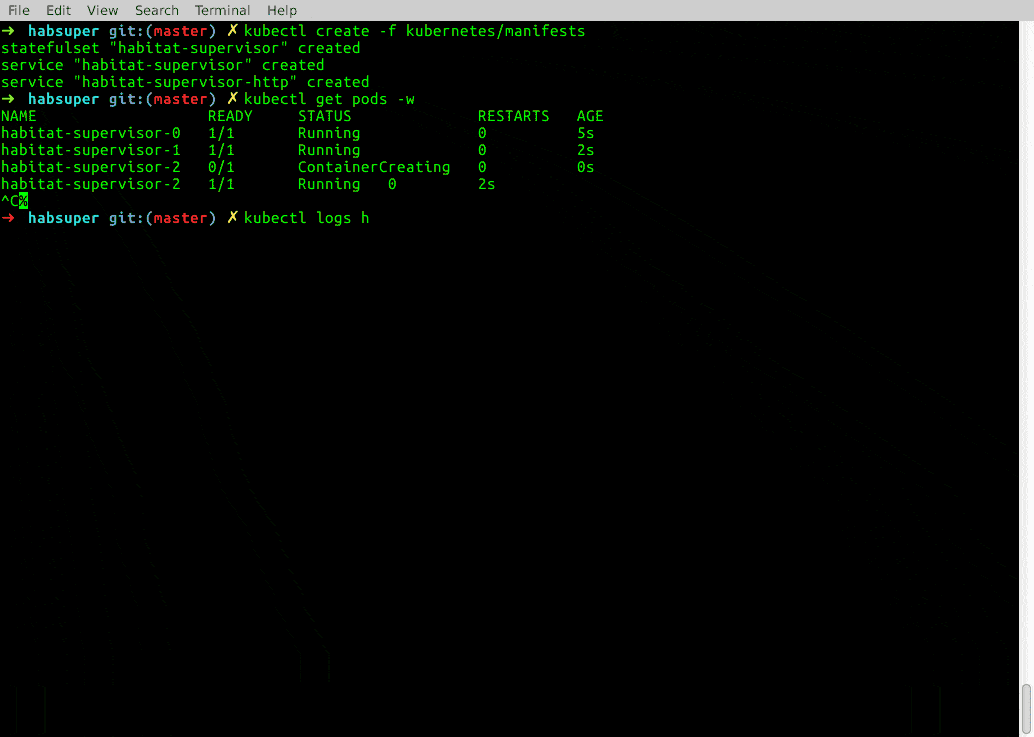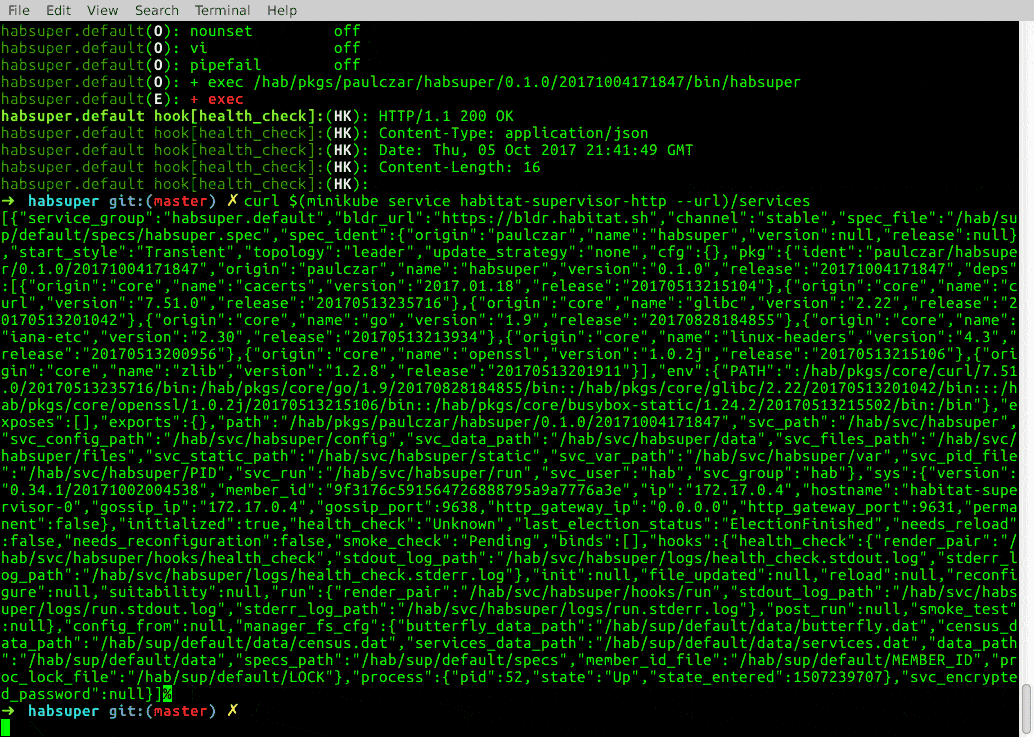
$ curl $(minikube service habitat-supervisor-http --url)/services
Conclusion
Hopefully this was enough to bootstrap a person looking to use Habitat on Kubernetes. It would be fairly trivial to use the manifests I provided and do one of the following:
-
Use the Habitat cluster created here as a permanent Habitat cluster and have your applications join and leave that cluster as they come up.
-
Swap out the use of
paulczar/habsupimage with your own image and adjust the ports and other values accordingly and have it run as a self contained cluster.
Getting Habitat to work in Kubernetes was fairly straight forward, however I had to do a few tricky things that shouldn’t be necessary. In order for Habitat to get solid adoption on Kubernetes I believe the following needs to be addressed:
-
Gossip cluster bootstrap relies on an ordered startup with
--peer ip-or-dns-of-first. Habitat should support a Kuberenetes based discovery which would ask the Kubernetes API to provide the peer details to join. -
The API should come online with an approriate health status before the cluster is created. This would allow the use of a readinessProbe and avoid the problem I suggested earlier.
-
Habitat should consider a mode that uses the Kubernetes APIs and the contents of the Manifest to configure itself rather than forming the gossip cluster.